Patient Deduplication
Although the online interface forces the user to perform a thorough search for a patient, duplications are still possible due to the following reasons that occur while performing a search:
- Variations in the spelling of the name
- Address changes
- Typographical errors
Overall, any difference between how the patient was originally entered and how it is searched for can result in the system not locating an exact match and, therefore, a duplicate patient can be entered.
The search process requires a minimum amount of search criteria to be entered. This information is fed into a sophisticated search algorithm that uses many different combinations of the information against the related database tables. If a patient is not found, the user is allowed to enter the patient as "new."
Batch loads to the registry are sent by organizations that independently maintain their own databases, which are basically their own listings of patients. Since they are maintaining their own databases of records, it is very possible to send duplicates. These duplications must be handled centrally at the registry as they are processed into the system.
There are two reasons why duplicates may be sent by batch:
- If there is a duplicate in the reporting database, the duplicates can be sent to the registry
- When a patient goes to another clinic that is not served by the same database, a duplicate record can be created and sent to the central registry.
When the records are sent via batch load, the data is stored in a holding table called the Pre-Reserve table. The data stays in this table until the Automatic Duplicate Identification Procedure, also referred to as the deduplication process, runs. The deduplication process moves the record, one record at a time, based on the process results. The record's end destinations, however, are the Reserve and Master tables. However, the duplicate identification result determines the record's actual end destination.
 For Louisiana users: As of IWeb version June 2018, manually entered vaccinations are not overwritten by HL7-sourced vaccinations. If a manually entered vaccination exists, it is automatically considered the best match. For Louisiana users: As of IWeb version June 2018, manually entered vaccinations are not overwritten by HL7-sourced vaccinations. If a manually entered vaccination exists, it is automatically considered the best match. |
Patient Deduplication Processes
Obviously, the goal is to avoid creating duplicate records for the same patient. This process is referred to deduplication or duplicate identification.
There are four processes that can determine whether a record in the database is a duplicate or not. The processes are:
- Automatic Duplicate Identification Procedure
- Deterministic (default)
- Probabilistic (a state-configurable property)
- Manual Duplicate Identification Procedure (manual deduplication)
- Automatic Master Duplication Procedure (scanning)
- Manual Master Duplication Procedure
The Manual Duplicate Identification Procedure uses the Manual Deduplication option. This process involves comparing both the incoming record and the database record and making a decision. Thus, this is a manual process.
The Automatic Duplicate Identification Process offers two different options: deterministic or probabilistic. However, the identification process is the same.
The Automatic Duplicate Identification Procedure uses the rule-based algorithm. It looks at the incoming data (IRMS# + Patient ID = Patient Identifier) record in the Pre-Reserve table and attempts to locate a match or similar record.
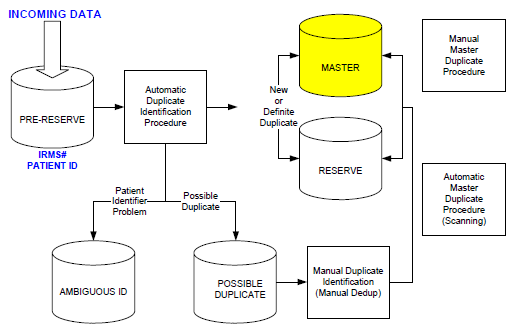
The image below shows the process, when the process may run, and the database tables a record might encounter.
For Montana Users: For patient records coming through HL7 messages and DTT, the following changes were made with the May 2018 release of
IWeb:
|
Database Tables for Record Storage
The database tables a record may encounter are as follows:
| Table | Description |
|
Pre-Reserve |
Holds patient records waiting to be processed into the Reserve and Master tables. When the data is loaded into the Pre-Reserve table, some of the fields are pre-processed. Both the Before and After process records are stored in the table. Addresses are pre-processed to ensure conformity to postal standards and spaces are removed. Names are pre-processed in three ways:
|
|
Reserve |
Stores the patient record exactly as it was sent from the Facility or IRMS. The Facility/IRMS database's IRMS number and patient ID are stored in this table so that the record can be mapped back to the Facility/IRMS database. |
|
Master |
Stores the latest patient record sent from a Facility/IRMS database. Each Reserve record that has been mapped to this Master record can reference it. The mapping of patient Reserve records to patient Master records is used to create a composite vaccination record by combining all of the vaccinations sent from the Facility/IRMS databases. |
|
Possible Duplicate |
Holds incoming patient records that have possible duplicate matches in the Reserve table. Records only go into this table if the Automatic Duplicate Identification Procedure could not definitely identify a duplicate record. Records in this table require human review using the Manual Duplication Identification or Manual Deduplication process. |
|
Ambiguous ID |
Holds incoming patient records that have Patient Identifier problems. Example: an IRMS sent patient 5 twice - referred to as patient 5a and patient 5b. Patient 5a has a different name than patient 5b. Records in this table require human review using the Ambiguous ID application. |
Records are moved from the Pre-Reserve table to the Master table once record at a time. The journey of a record to the Master table depends on whether another patient record is found to be similar or a definite match.
The record match result will be one of the following:
- New Record - a match was NOT located.
- Duplicate Record - a match was located. For example, if the street address/state/zip code or street address/city matches the record in the Reserve table, the end result is a duplicate.
- Possible Duplicate - unsure if a match was located.
- Patient Identifier Problems - unique Patient Identifier is no longer unique. A separate module, Ambiguous ID, is used by the registry administrator to review and determine whether the record represents the same person or not. For version 4.2, if two records come in from the same IRMS, the newest record always overwrites the existing record, except in cases where the newest record has a null value (keeping what is in the original record rather than keeping the blank field).
-
- The existing property Enable Separate During Ambiguous ID was disabled.
- The logic was modified to process ambiguous ID decisions, so if the administrator has chosen to process the incoming records, the newest record will not overwrite any existing values with null (the newest record currently overwrites all existing values).
- This new logic executes both when the user reviews the ambiguous ID records manually and selects to accept the new record, and when the user selects Process IRMS to process all records without looking at them individually.
- If the incoming record is intentionally nulling a column, such as an instance when the SSN was incorrect and the correct one is not known, this logic prevents that from being corrected and the user must manually update it in IWeb.
The deduplication rules/logic differ between Deterministic and Probabilistic.
|
|
 |